Ľý”ŕ∂ŗ żĺ›ľĮŃ™ļŌ—ĶŃ∑Ķń…Ó∂»—ßŌįń£–ÕŌ‘÷ÝŐŠ…żľÓĽýĪŗľ≠ĽÓ–‘‘§≤‚ĺę∂»
°∂Nature Communications°∑£ļDeep learning models simultaneously trained on multiple datasets improve base-editing activity prediction
°ĺ◊÷ŐŚ£ļ
īů
÷–
–°
°Ņ
Īľš£ļ2025ńÍ11‘¬08»’
ņī‘ī£ļNature Communications 15.7
Īŗľ≠Õ∆ľŲ£ļ
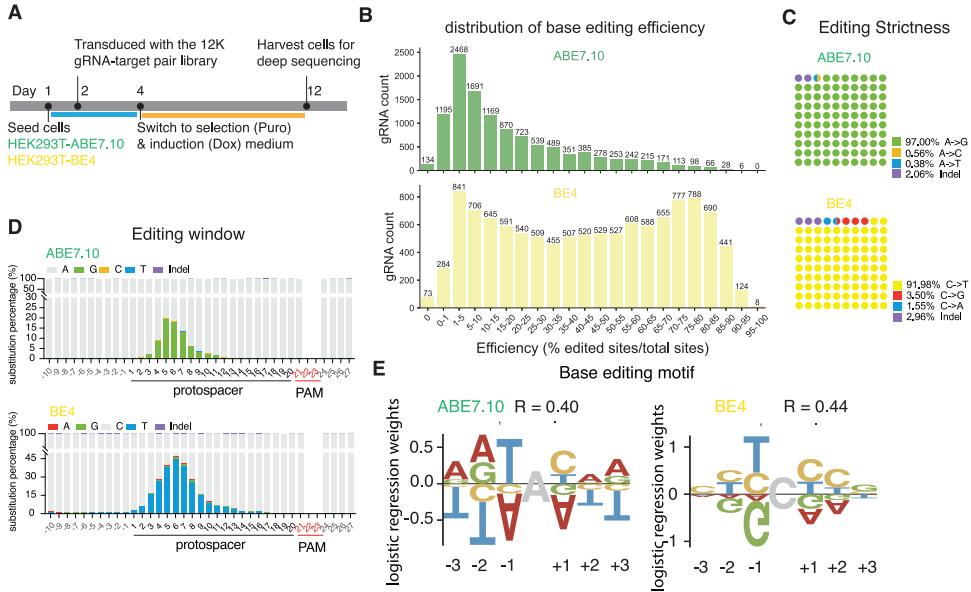
°°°°Īĺ—–ĺŅ’Ž∂‘Ō÷”–ľÓĽýĪŗľ≠∆ų£®BE£©gRNA…Ťľ∆Ļ§ĺŖ‘§≤‚◊ľ»∑–‘≤Ľ◊„Ķńő Ő‚£¨Ņ™∑ĘŃňń‹ĻĽÕ¨ ĪņŻ”√∂ŗłŲ“ž÷ żĺ›ľĮĹÝ––—ĶŃ∑Ķń…Ó∂»—ßŌįń£–ÕCRISPRon-ABE/CBE°£ł√ń£–ÕÕ®Ļż’ŻļŌīůĻśń£ Ķ—ť żĺ›£®‘ľ20,000ŐűgRNA£©£¨ ĶŌ÷Ńň∂‘ŌŔŗ—Ŗ ľÓĽýĪŗľ≠∆ų£®ABE£©ļÕįŻŗ◊ŗ§ľÓĽýĪŗľ≠∆ų£®CBE£©Īŗľ≠–߬ ľįĹŠĻŻ∆Ķ¬ Ķńĺę◊ľ‘§≤‚£¨≤Ę÷ß≥÷”√Ľßłýĺ›Őō∂®ľÓĽýĪŗľ≠∆ų£®»ÁABE7.10°ĘABE8e°ĘBE4£©ĹÝ–– żĺ›ľĮľ”»®ĶńŐō“ž–‘‘§≤‚£¨ő™ĺę◊ľĽý“Ú◊ťĪŗľ≠ŐŠĻ©ŃňłŁŅ…ŅŅĶń…Ťľ∆Ļ§ĺŖ°£
°°°°
‘ŕĽý“Ú◊ťĪŗľ≠Ńž”Ú£¨CRISPR-Cas9ľľ űłÔ√Ł–‘ĶōłńĪšŃň…ķ√ŁŅ∆—ß—–ĺŅ∑Ĺ Ĺ°£»Ľ∂Ý£¨īęÕ≥ĶńCRISPR-Cas9“ņņĶ”ŕ≤ķ…ķDNAňęŃī∂ŌŃ—£®DSB£©£¨’‚ĽŠ“ż∑Ę≤ĽŅ…ŅōĶń≤Ś»ŽĽÚ»Ī ߣ®indel£©ÕĽĪš£¨Ōř÷∆Ńň∆š‘ŕĺę◊ľ“ĹŃ∆÷–Ķń”¶”√°£ő™ŃňŅň∑Ģ’‚“Ľĺ÷Ōř£¨ľÓĽýĪŗľ≠∆ų£®Base Editors, BEs£©”¶‘ň∂Ý…ķ£¨ňŁÕ®ĻżĹęCas9«–Ņŕ√ł”ŽÕ—įĪ√ł»ŕļŌ£¨ń‹ĻĽ‘ŕ≤Ľ∂ŌŃ—DNAňęŃīĶń«ťŅŲŌ¬ ĶŌ÷Ķ•ļň‹’ňŠĶńĺę◊ľŐśĽĽ°£
ĺ°Ļ‹ľÓĽýĪŗľ≠∆ų’ĻŌ÷≥Ųĺřīů«ĪѶ£¨Ķę∆šĪŗľ≠–߬ ‹ĶĹŌÚĶľRNA£®gRNA£©…Ťľ∆ļÕĪŗľ≠őĽ÷√ĶńŌ‘÷Ý”įŌž°£Ō÷”–Ķń‘§≤‚Ļ§ĺŖīů∂ŗĽý”ŕĶ•“Ľ żĺ›ľĮŅ™∑Ę£¨«“ żĺ›ľĮ÷–įŁļ¨īůŃŅĶՖ߬ gRNA£¨Ķľ÷¬‘§≤‚◊ľ»∑–‘”–Ōř°£łŁłī‘”Ķń «£¨≤ĽÕ¨ Ķ—ť “ Ļ”√ĶńÕ—įĪ√łĪšŐŚ£®»ÁABE7.10°ĘABE8e°ĘBE4Ķ»£©ļÕgRNAőńŅ‚īś‘ŕŌ‘÷Ý≤Ó“ž£¨ ĻĶ√ żĺ›ľĮ÷ģľšń—“‘÷ĪĹ”’ŻļŌņŻ”√°£’‚÷÷ żĺ›“ž÷ –‘ő Ő‚—Ō÷ō÷∆‘ľŃňłŖ–ßgRNAĶń…Ťľ∆ļÕľÓĽýĪŗľ≠ľľ űĶńĻ„∑ļ”¶”√°£
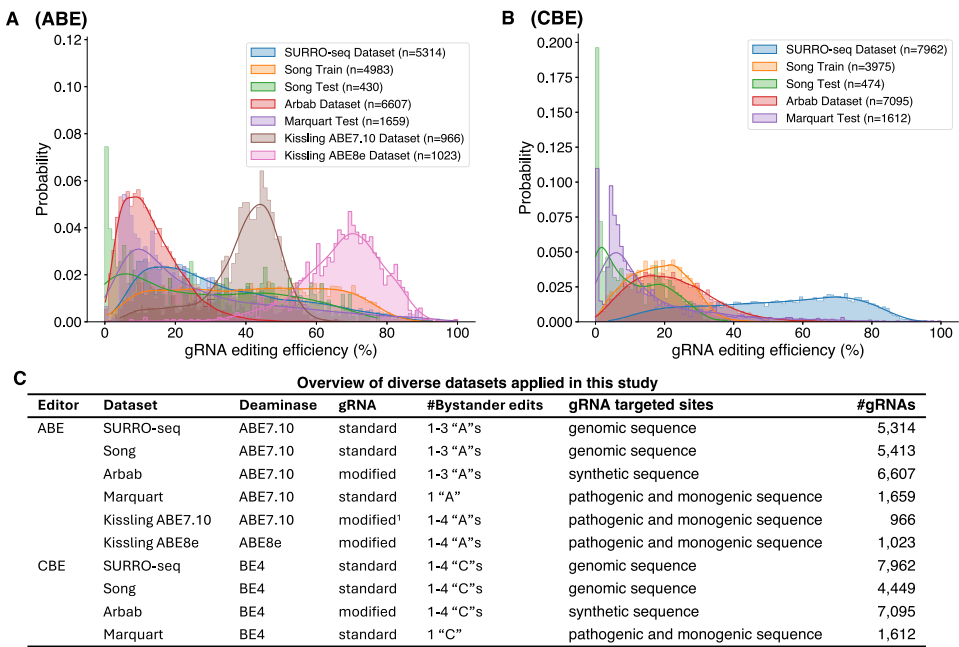
ő™ŃňĹ‚ĺŲ’‚–©ŐŰ’Ĺ£¨ņī◊‘łÁĪĺĻĢłýīů—ß°Ęį¬ļķňĻīů—ßĶ»ĽķĻĻĶń—–ĺŅÕŇ∂”‘ŕ°∂Nature Communications°∑…Ō∑ĘĪŪŃňňŻ√«Ķń◊Ó–¬—–ĺŅ≥…ĻŻ°£ňŻ√«Õ®Ļż”¶”√Ō»«įĹ®ŃĘĶń¬ż≤°∂ĺgRNA-į–Ķ„∂‘őńŅ‚ľľ ű£®SURRO-seq£©£¨‘ŕHEK293TŌłįŻ÷–īůĻśń£≤‚ŃŅŃňŃĹ÷÷ľÓĽýĪŗľ≠∆ų£®ABE7.10ļÕBE4-Gam£©ĶńĪŗľ≠–߬ £¨√Ņ÷÷Īŗľ≠∆ų∆ņĻņŃň‘ľ11,500ŐűgRNA°£ĹŠļŌ“—∑ĘĪŪĶń żĺ›ľĮ£¨—–ĺŅ»ň‘Ī◊Ó÷’’ŻļŌŃň17,941ŐűABE gRNAļÕ19,010ŐűCBE gRNAĶń żĺ›£¨ő™ń£–ÕŅ™∑ĘŐŠĻ©Ńň∑ŠłĽ◊ ‘ī°£
—–ĺŅ»ň‘Ī∑ĘŌ÷£¨ABE7.10÷ų“™ ĶŌ÷A°§TĶĹG°§CĶń◊™ĽĽ£®—ŌłŮ–‘īÔ98.5%£©£¨∂ÝBE4÷ų“™ ĶŌ÷C°§GĶĹT°§AĶń◊™ĽĽ£®—ŌłŮ–‘92%£©°£ŃĹ÷÷Īŗľ≠∆ų‘ŕ‘≠–ÕľšłŰ«Ý4-8őĽĶńļň–ńĪŗľ≠īįŅŕĪŪŌ÷≥Ų◊ÓłŖĪŗľ≠–߬ °£”–»§Ķń «£¨ľÓĽýĪŗľ≠–߬ ”ŽĽĮŇßŃī«ÚĺķCas9£®SpCas9£©”’ĶľĶńindel∆Ķ¬ ≥ ’żŌŗĻō£®ABE7.10ĶńR=0.40-0.54£¨BE4ĶńR=0.29-0.49£©£¨’‚ĪŪ√ųCas9–߬ ‘§≤‚∂‘ľÓĽýĪŗľ≠‘§≤‚ĺŖ”–÷ō“™≤őŅľľŘ÷Ķ°£
—–ĺŅÕŇ∂”Ķńļň–ńīī–¬‘ŕ”ŕŅ™∑ĘŃňń‹ĻĽÕ¨ ĪņŻ”√∂ŗłŲ żĺ›ľĮĶń…Ó∂»—ßŌįń£–ÕCRISPRon-ABEļÕCRISPRon-CBE°£”ŽŌ÷”–ĹŲ‘§≤‚ĹŠĻŻ∆Ķ¬ ≤Ęī”÷–Õ∆∂ŌgRNA–߬ Ķńń£–Õ≤ĽÕ¨£¨ł√ń£–Õń‹ĻĽī”30ļň‹’ňŠ£®nt£©Ķń š»ŽDNAį––ÚŃ–Õ¨ Ī‘§≤‚gRNA–߬ ļÕĹŠĻŻ∆Ķ¬ °£ń£–Õ š»ŽįŁņ®Ķ•»»Īŗ¬ŽĶń30nt DNA–ÚŃ–°ĘĪŗľ≠īįŅŕńŕŅ…Īŗľ≠őĽ÷√ĶńĪÍľ«°ĘgRNA-DNAĹŠļŌń‹£®¶§GB£©“‘ľį‘§≤‚ĶńCas9–߬ °£
◊ÓĻōľŁĶń «£¨—–ĺŅ»ň‘Ī“ż»ŽŃň“Ľ÷÷ żĺ›ľĮł–÷™£®dataset-aware£©—ĶŃ∑≤Ŗ¬‘£¨Õ®Ļżő™√ŅłŲ żĺ›Ķ„ŐŪľ”ĪŪ ĺ∆šņī‘īĶńĪÍ«©ŌÚŃŅ£¨ Ļń£–Õń‹ĻĽ"÷™ŌĢ"√ŅłŲ—ĶŃ∑—ýĪĺĶń żĺ›ľĮņī‘ī°£‘ŕ‘§≤‚ Ī£¨”√ĽßŅ…“‘Õ®ĻżĶų’ŻĪÍ«©ŌÚŃŅ÷–Ķń»®÷ō£¨«ŅĶų”ŽńŅĪÍľÓĽýĪŗľ≠∆ų◊ÓŌŗĻōĶń żĺ›ľĮ°£ņż»Á£¨’Ž∂‘ABE8eĶń…Ťľ∆£¨Ņ…“‘łÝ”ŤKissling ABE8e żĺ›ľĮ100%Ķń»®÷ō£Ľ∂Ý∂‘”ŕ∆ĹŐ®≤Ľ√ų»∑ĶńABE7.10ĽÚBE4…Ťľ∆£¨‘ÚŅ…“‘∆Ĺĺýľ”»®∂ŗłŲ żĺ›ľĮ°£
ń£–Õ Ļ”√∂Ģő¨∆§∂Ż—∑ŌŗĻōŌĶ ż£®R2£©ļÕňĻ∆§∂Ż¬ŁĶ»ľ∂ŌŗĻōŌĶ ż£®¶—2£©ĹÝ––∆ņĻņ£¨’‚–©÷łĪÍń‹ĻĽŃ™ļŌ∆ņĻņgRNAĪŗľ≠–߬ ļÕĹŠĻŻ∆Ķ¬ Ķń‘§≤‚–‘ń‹°£‘ŕ∂ņŃĘ≤‚ ‘ľĮ…ŌĶń∆ņĻņĪŪ√ų£¨CRISPRon-ABE/CBEŌ‘÷ݔҔŕŌ÷”–Ļ§ĺŖ°£ŐōĪū «£¨ĶĪ‘ŕ—ĶŃ∑÷– °¬‘ żĺ›ľĮĪÍ«© Ī£¨ń£–Õ–‘ń‹Ō¬ĹĶ‘ľ10%£¨’‚÷§ ĶŃň żĺ›ľĮł–÷™≤Ŗ¬‘‘ŕ’ŻļŌ“ž÷ żĺ› ĪĶń÷ō“™–‘°£
—–ĺŅ≤…”√SURRO-seqľľ ű£¨‘ŕHEK293TŌłįŻ÷–ĻĻĹ®∂ŗőųĽ∑ňō”’ĶľĶńABE7.10ļÕBE4ő»∂®ŌłįŻŌĶ£¨Õ®Ļż¬ż≤°∂ĺőńŅ‚◊™Ķľ£®ł–»ĺłī żMOI=0.3£©≤ĘņŻ”√į–ŌÚ…Ó∂»≤‚–Ú£®MGISEQ-2000∆ĹŐ®£©ĽŮ»°īůĻśń£Īŗľ≠ żĺ›°£Õ®Ļż∂ŗ≤Ĺ÷Ť żĺ›Ļż¬ňļÕ÷ ŃŅŅō÷∆£¨Ī£ŃŰ÷ß≥÷∂Ń ż°›100ĶńgRNA£¨◊Ó÷’ĽŮĶ√11,484ŐűABE gRNAļÕ11,406ŐűCBE gRNAĶńłŖ÷ ŃŅ żĺ›ľĮ°£…Ó∂»—ßŌįń£–ÕĽý”ŕKeras/TensorFlowŅÚľ‹Ņ™∑Ę£¨≤…”√įŁļ¨∂ŗ≥Ŗ∂»ĺŪĽż…Ůĺ≠ÕݬÁļÕ»ęѨŔ≤„Ķńľ‹ĻĻ£¨Õ®Ļż5’ŘĹĽ≤ś—ť÷§ļÕ∂ŗīőňśĽķ÷÷◊”÷ōłī—ĶŃ∑»∑Ī£ĹŠĻŻő»Ĺ°–‘°£
īůĻśń£ABEļÕCBEĪŗľ≠–߬ ”ŽĹŠĻŻĶńŃŅĽĮ∑÷őŲ
Õ®ĻżSURRO-seqľľ ű£¨—–ĺŅ»ň‘Ī≥…Ļ¶…ķ≥…Ńňĺý‘»–‘łŁłŖĶńABEļÕCBEĪŗľ≠ żĺ›°£∑÷őŲŌ‘ ĺ£¨ABE7.10÷ų“™ ĶŌ÷A°§TĶĹG°§CĶń◊™ĽĽ£®—ŌłŮ–‘98.5%£©£¨∂ÝBE4÷ų“™ ĶŌ÷C°§GĶĹT°§AĶń◊™ĽĽ£®—ŌłŮ–‘92%£©°£ŃĹ÷÷Īŗľ≠∆ų‘ŕ‘≠–ÕľšłŰ«Ý4-8őĽĶńļň–ńĪŗľ≠īįŅŕĪŪŌ÷≥Ų◊ÓłŖĪŗľ≠–߬ £¨«“ľÓĽýĪŗľ≠–߬ ”ŽSpCas9”’ĶľĶńindel∆Ķ¬ ≥ ’żŌŗĻō°£–ÚŃ–ń£ŐŚ∑÷őŲĹÝ“Ľ≤ĹĹ“ ĺŃňĪŗľ≠őĽĶ„≤ŗ“Ū–ÚŃ–∂‘Īŗľ≠–߬ Ķń”įŌž£¨»ÁABE7.10∂‘5'TAC–ÚŃ–£®ī÷ŐŚő™Īŗľ≠őĽĶ„£©ĺŖ”–łŖĪŗľ≠ĽÓ–‘£¨∂Ý∂‘5'AAA–ÚŃ–Īŗľ≠ĽÓ–‘ĶÕ°£
żĺ›ľĮł–÷™Ķń…Ó∂»—ßŌįń£–ÕŐŠ…żľÓĽýĪŗľ≠∆ų–߬ ļÕĹŠĻŻ∆Ķ¬ ‘§≤‚
”ŽŌ÷”–ń£–ÕŌŗĪ»£¨CRISPRon-ABE/CBEń‹ĻĽÕ¨ Ī‘§≤‚gRNA–߬ ļÕĹŠĻŻ∆Ķ¬ £¨≤Ę≤…”√ żĺ›ľĮł–÷™—ĶŃ∑≤Ŗ¬‘°£ń£–ÕÕ®Ļż“ż»ŽĪŪ ĺ żĺ›ľĮņī‘īĶńĪÍ«©ŌÚŃŅ£¨ Ļ‘§≤‚ń‹ĻĽĽý”ŕ—ĶŃ∑ żĺ›ľĮĶńľ”»®◊ťļŌ°£”√ĽßŅ…łýĺ›ńŅĪÍľÓĽýĪŗľ≠∆ųņŗ–Õ£®»ÁABE7.10°ĘABE8eĽÚBE4£©ļÕ Ķ—ť∆ĹŐ®—°‘ŮŌŗ”¶Ķń»®÷ō…Ť÷√°£‘ŕ∂ŗłŲ∂ņŃĘ≤‚ ‘ľĮ…ŌĶń∆ņĻņĪŪ√ų£¨ł√ń£–Õ–‘ń‹Ō‘÷ݔҔŕŌ÷”–Ļ§ĺŖ£¨«“ żĺ›ľĮĪÍ«©Ķń“ż»Ž Ļ–‘ń‹ŐŠ…ż‘ľ10%°£
Ľý◊ľ≤‚ ‘Ō‘ ĺ£¨CRISPRon-ABE/CBE‘ŕ∂ŗłŲ∂ņŃĘ≤‚ ‘ľĮ…Ōĺý”Ň”ŕDeepABE/CBE°ĘBE-HIVE°ĘBE-DICTĶ»Ō÷”–∑Ĺ∑®°£Õ®ĻżSHAP∑÷őŲļÕŌŻ»ŕ Ķ—ť÷§ Ķ£¨‘§≤‚ĶńCRISPR-Cas9–߬ ‘ŕľÓĽýĪŗľ≠∆ų–߬ ‘§≤‚÷–∆ū÷ō“™◊ų”√°£ń£–ÕĽĻ’Ļ ĺŃň‘ŕ≤ĽÕ¨ŌłįŻŌĶ£®»ÁmESCļÕU2OS£©…ŌĶńŃľļ√∑ļĽĮń‹Ń¶£¨ĺ°Ļ‹ĶĪ«įń£–ÕĹŲĽý”ŕHEK293TŌłįŻ żĺ›—ĶŃ∑°£
Īĺ—–ĺŅÕ®Ļż…ķ≥…īůĻśń£ľÓĽýĪŗľ≠ żĺ›ļÕŅ™∑Ęīī–¬Ķń…Ó∂»—ßŌįŅÚľ‹£¨Ō‘÷ÝŐŠ…żŃňľÓĽýĪŗľ≠ĽÓ∂ĮĶń‘§≤‚◊ľ»∑–‘°£CRISPRon-ABE/CBEń£–ÕĶńļň–ń”Ň ∆‘ŕ”ŕ∆šń‹ĻĽÕ¨ ĪņŻ”√∂ŗłŲ“ž÷ żĺ›ľĮĹÝ––—ĶŃ∑£¨≤ĘÕ®Ļż żĺ›ľĮł–÷™Ľķ÷∆ ĶŌ÷’Ž∂‘Őō∂®ľÓĽýĪŗľ≠∆ųĶńĺę◊ľ‘§≤‚°£ł√—–ĺŅ≤ĽĹŲĹ‚ĺŲŃňĶĪ«įľÓĽýĪŗľ≠‘§≤‚Ļ§ĺŖĶń żĺ›Ōř÷∆ļÕ“ž÷ –‘ő Ő‚£¨ĽĻő™łŁĻ„∑ļĶńCRISPRľľ ű£®»ÁPrime Editing£©÷–Ķń żĺ›’ŻļŌŐŠĻ©ŃňŅ…––≤Ŗ¬‘°£
—–ĺŅ»ň‘ĪŐŠĻ©Ķń‘ŕŌŖÕݬÁ∑ĢőŮ∆ųļÕ∂ņŃĘ»ŪľĢ£®https://rth.dk/resources/crispr/£© Ļ»ę«ÚŅ∆—–»ň‘Īń‹ĻĽĪ„Ĺ›ĶōņŻ”√’‚“ĽĻ§ĺŖĹÝ––gRNA…Ťľ∆°£ĺ°Ļ‹ĶĪ«įń£–ÕĹŲļ≠ł«ABE7.10°ĘABE8eļÕBE4Ķ»”–Ōřņŗ–ÕĶńľÓĽýĪŗľ≠∆ų£¨«“÷ų“™Ľý”ŕHEK293TŌłįŻ żĺ›£¨Ķę—–ĺŅ’Ļ ĺĶń żĺ›’ŻļŌ≤Ŗ¬‘ő™őīņīń…»ŽłŁ∂ŗľÓĽýĪŗľ≠∆ųĪšŐŚļÕŌłįŻŌĶ żĺ›Ķž∂®ŃňĽýī°°£’‚ŌÓ—–ĺŅő™Õ∆∂Įĺę◊ľĽý“Ú◊ťĪŗľ≠Ļ§ĺŖĶń∑Ę’ĻļÕŃŔī≤”¶”√¬ű≥ŲŃň÷ō“™“Ľ≤Ĺ°£
 …ķőÔÕ®őĘ–ŇĻę÷ŕļŇ
…ķőÔÕ®őĘ–ŇĻę÷ŕļŇ
 …ķőÔÕ®–¬ņňőĘ≤©
…ķőÔÕ®–¬ņňőĘ≤©
- ň—ňų
- Ļķľ
- Ļķńŕ
- »ňőÔ
- ≤ķ“Ķ
- »»Ķ„
- Ņ∆∆’
ĹŮ»’∂ĮŐ¨ |
»ň≤Ň –≥° |
–¬ľľ ű◊®ņł |
÷–ĻķŅ∆—ß»ň |
‘∆’ĻŐ® |
BioHot |
‘∆Ĺ≤Ő√÷Ī≤• |
ĽŠ’Ļ÷––ń |
ŐōľŘ◊®ņł |
ľľ űŅž—∂ |
√‚∑— ‘”√
įś»®ňý”– …ķőÔÕ®
Copyright© eBiotrade.com, All Rights Reserved
Ń™ŌĶ–ŇŌš£ļ
‘ŃICPĪł09063491ļŇ