
-

生物通官微
陪你抓住生命科技
跳动的脉搏
生物通官微
陪你抓住生命科技
跳动的脉搏
综述:高收入国家无家可归者预测模型:一项范围综述
《BMC Public Health》:Homelessness prediction models in high-income countries: a scoping review
【字体: 大 中 小 】 时间:2025年11月18日 来源:BMC Public Health 3.6
编辑推荐:
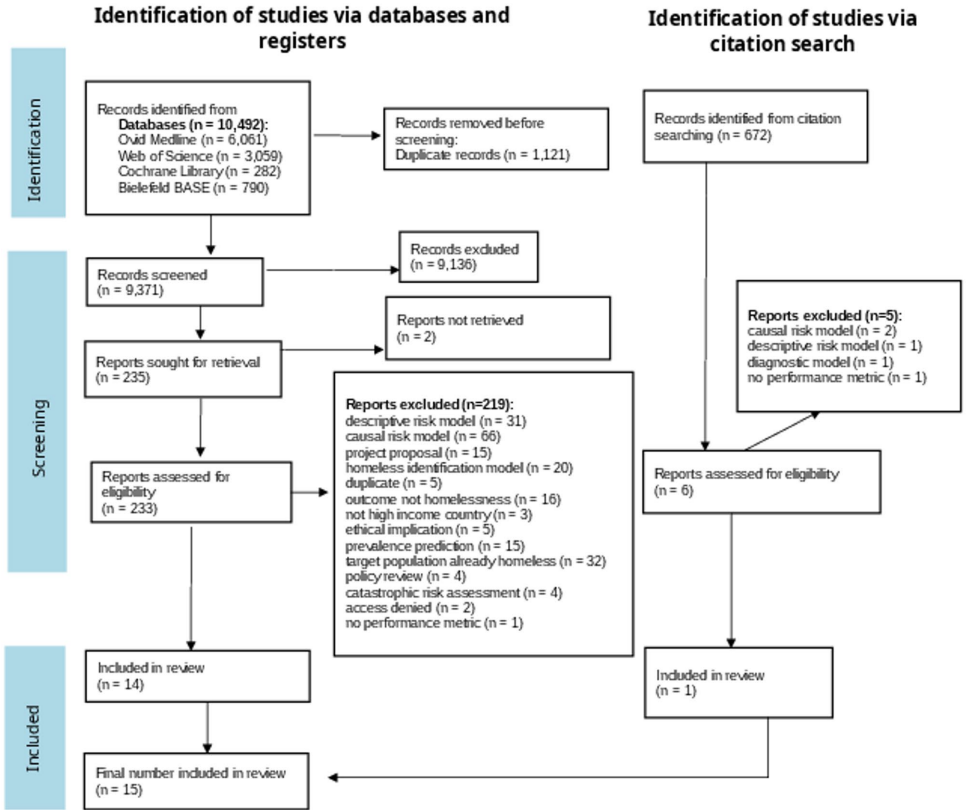
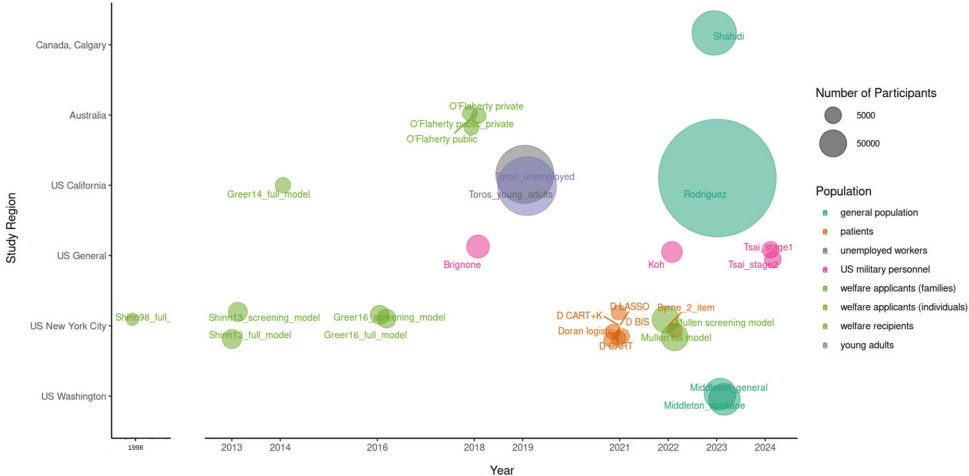
本范围综述系统梳理了高收入国家中预测未来无家可归风险的模型,揭示了该领域研究的高度异质性。分析涵盖的15项研究(主要来自美国)显示,模型多采用逻辑回归(Logistic Regression)或考克斯回归(Cox Regression),仅少数结合机器学习(Machine Learning, ML)算法。研究强调,尽管这些模型在精准定位高风险人群、提升预防项目效率方面潜力巨大,但存在外部验证严重不足(仅2个模型)、校准指标使用有限等关键局限。作者呼吁未来研究应聚焦于模型评估、伦理考量及数据保护,以推动其向现实世界的有效转化。
 生物通微信公众号
生物通微信公众号
知名企业招聘

